Cómo empecé a hablar con la IA desde la aplicación de escritorio gvSIG desktop
¿Alguna vez has querido preguntarle a tu aplicación qué datos tiene o qué puede hacer con ellos, usando tus propias palabras? Esa fue la pregunta que me hice a principios de este año cuando empecé a ver que los modelos de lenguaje (LLMs, Large Language Models o Modelos de Lenguaje Grande) podían hacer cosas increíbles… pero siempre desde un navegador web, lejos de la aplicación de escritorio.
Como muchos sabéis, llevo años trabajando en gvSIG Desktop, una aplicación Java de escritorio con mucha historia y mucho código. La idea de integrar capacidades de IA directamente en la aplicación me pareció fascinante, pero tenía un problema: todo lo que veía requería frameworks complejos de Python o soluciones en la nube que no encajaban con nuestra realidad, requerian versiones modernas de java o python con las que no podia contar.
Así que me dije “voy a intentar hacerlo a mi manera”. Voy a contaros cómo, en unos dias, conseguí que gvSIG desktop empezara a conversar con Gemini usando poco más que las librerías HTTP de Java y Jython.
El primer paso, un chat simple pero funcional
Lo primero que necesitaba era lo más básico, una ventana de chat dentro de gvSIG desktop que pudiera enviar mensajes a la API de Gemini y mostrar las respuestas.
Para mantener las cosas simples, usé el entorno de scripting y Jython para prototipar rápidamente la interfaz de usuario, y para la comunicación con la API, me bastó con las librerías HTTP de Java.
El núcleo de la comunicación se reducía a esto: construir el payload JSON correcto y enviarlo.
from java.net import URL, HttpURLConnection
from java.io import BufferedReader, InputStreamReader, OutputStreamWriter
from javax.json import Json
class GeminiClient:
def __init__(self):
self.history = []
self.api_key = "tu_api_key"
self.api_url = "https://generativelanguage.googleapis.com/v1/models/gemini-pro:generateContent"
def send_message(self, user_prompt):
# Construir la solicitud HTTP
url = URL(self.api_url + "?key=" + self.api_key)
conn = url.openConnection()
conn.setRequestMethod("POST")
conn.setRequestProperty("Content-Type", "application/json")
conn.setDoOutput(True)
# Construir el payload JSON
payload = {
"contents": [{
"parts": [{"text": user_prompt}]
}]
}
# Enviar la solicitud
output_stream = conn.getOutputStream()
writer = OutputStreamWriter(output_stream, "UTF-8")
writer.write(Json.createObjectBuilder(payload).build().toString())
writer.flush()
# Leer la respuesta
reader = BufferedReader(InputStreamReader(conn.getInputStream()))
response = ""
line = reader.readLine()
while line is not None:
response += line
line = reader.readLine()
return response
La magia estaba en construir el Json correcto que espera la API de Gemini. Pero una vez resuelto esto, en pocas horas ya tenía una ventana de chat funcionando dentro de gvSIG.
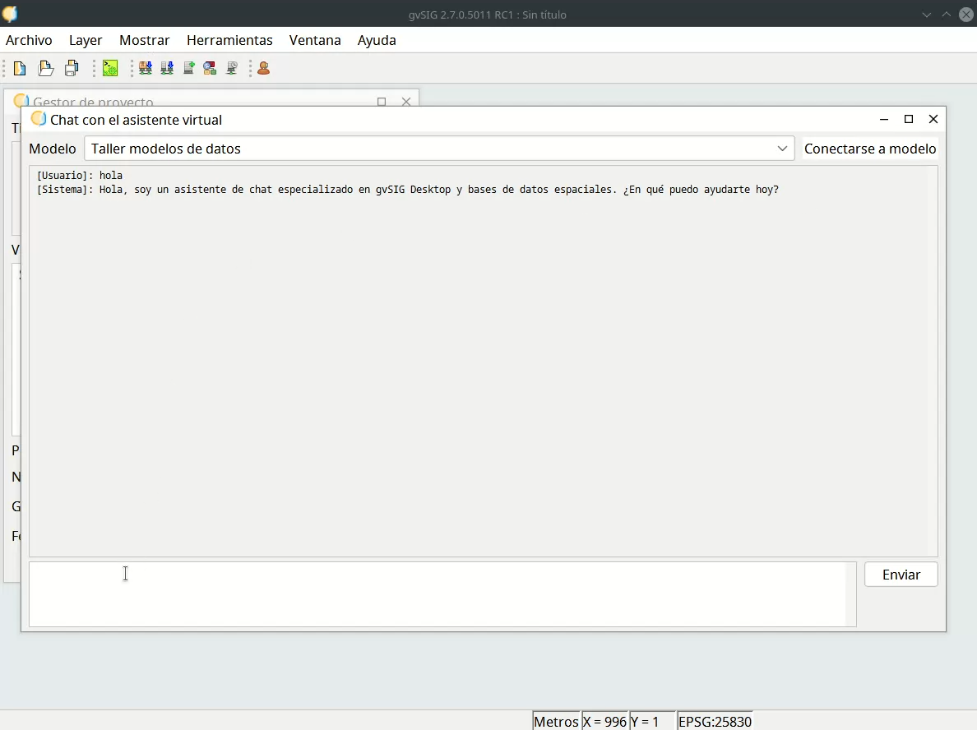
El primer prototipo era sencillo, pero funcionaba. Podía escribir preguntas y obtener respuestas.
El desafío real, más allá del chat conversacional
Un chat conversacional está bien para hacer pruebas, pero no es muy útil en una aplicación de escritorio. El verdadero reto era cómo usar el LLM para algo práctico. En nuestro caso, se me ocurrió que podría ayudar con la ficha de búsqueda de gvSIG, que aunque es potente, puede resultar compleja para los usuarios.
Pero aquí aparecía otro problema ¿cómo le pido al LLM que trabaje con mis datos sin enviarle información sensible, sin enviarle los datos de las capas que tengo cargadas la la aplicación? La solución fue enseñarle a entender la estructura de mis datos, no darle los datos en sí.
El arte del prompting estructurado, enseñándole las reglas del juego
La verdadera magia no estaba en la conexión HTTP o en la cacharreria Json que habia que hacer para hablar con el LLM, sino en el diseño del system prompt que conseguiría que el LLM entendiera exactamente cómo tenía que comportarse, estaba programando con palabras. El prompt se convirtió en el cerebro del sistema, las reglas del juego que transformaban un modelo de lenguaje genérico en un especialista de gvSIG desktop.
El desafío era triple:
- Contexto: Darle al LLM información suficiente sobre la estructura de los datos
- Comportamiento: Definir exactamente cómo debía responder para cada tipo de consulta
- Formato: Forzar una salida estructurada y parseable
El prompt base tenía que establecer las reglas fundamentales.
La estructura del esqueleto principal del prompt que construí fue algo parecido a esto:
BASE_PROMPT = u"""
Eres un asistente especializado en gvSIG Desktop.
Responde EXCLUSIVAMENTE en castellano con objetos JSON válidos.
TIPOS DE CONSULTA SOPORTADOS:
- "text": Para consultas generales
- "sql": Para consultas SQL sobre las tablas
- "plantuml": Para diagramas de entidad-relación
REGLAS ESTRICTAS PARA SQL:
- ⛔ Nunca incluyas esquemas en las consultas
- ✅ Usa solo SQL-92 estándar
- 🌍 Solo funciones espaciales de SQL/MM y OGC SFS
- 🚫 Evita sintaxis no estándar
- 📏 Limita a 1000 resultados
ESTRUCTURA DE RESPUESTA OBLIGATORIA:
{
"type": "tipo_de_respuesta",
// campos adicionales según el tipo
}
EJEMPLO SQL:
{
"type": "sql",
"sql": "SELECT * FROM tabla WHERE condición LIMIT 1000;",
"title": "Descripción clara",
"esValorEscalar": false
}
EJEMPLO PLANTUML:
{
"type": "plantuml",
"diagram": "@startuml\\nentity Tabla\\n@enduml",
"title": "Diagrama de entidades"
}
"""
Con estas reglas, el LLM ya no solo conversaba, sino que generaba instrucciones. La aplicación actuaba como un intérprete: recibía un JSON, miraba el campo “type” y sabía exactamente qué hacer. Si recibía {“type”: “sql”, …}, sabía que debía mostrar un botón que, al pulsarlo, ejecutaría la consulta SQL. Si recibía {“type”: “plantuml”, …}, generaría un botón para visualizar el diagrama.
Los resultados, cuando todo empezó a encajar
La primera vez que probé el sistema completo me resulto impactante. El LLM dejó de ser un simple chatbot para convertirse en un motor de análisis que respondía a mis preguntas con acciones concretas. Una conversación natural se traducía en operaciones reales dentro de gvSIG:
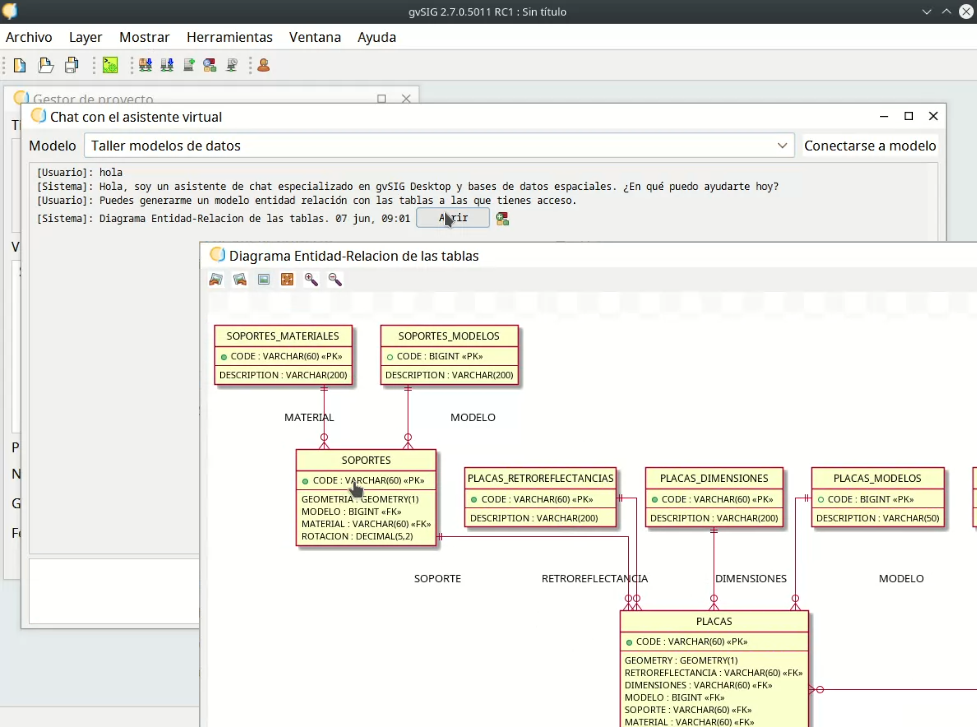
En esta captura se ve cómo el usuario pregunta “Puedes generarme un modelo entidad relación con las tablas a las que tienes acceso?” y el sistema responde con un botón que al hacer clic muestra el diagrama solicitado.
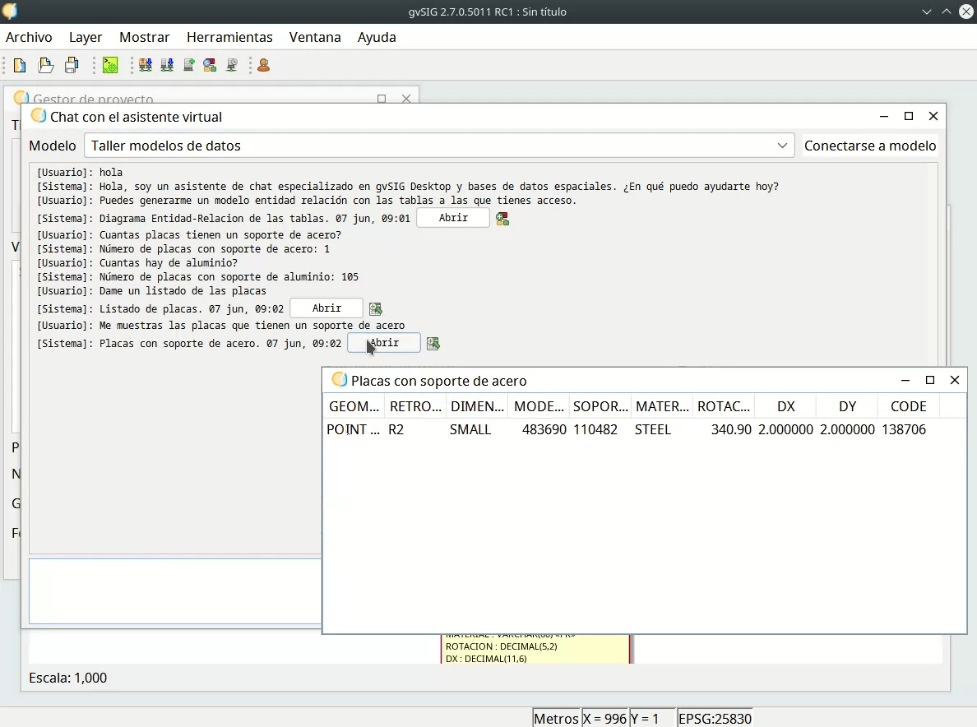
Aquí vemos cómo la orden de “Muestrame las placas que tienen un soporte de acero” el sistema genera una consulta SQL y responde con un botón que al hacer clic muestra el resultado en una tabla.
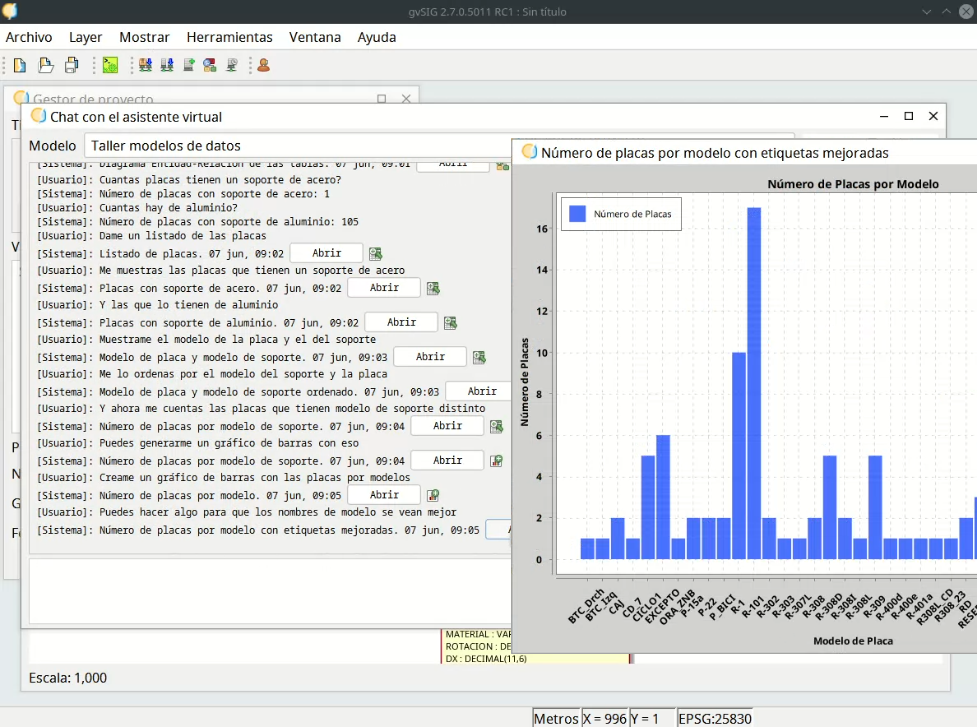
Finalmente, una solicitud más compleja como un gráfico de barras se traduce en la visualización de este en la aplicación.
Cada respuesta del sistema correspondía a un Json estructurado que el LLM generaba y que la aplicación parseaba y ejecutaba, mostrando los resultados en tablas o gráficos según el caso.
Detalles de implementación para desarrolladores
La comunicación con la API de Gemini
Implementé un cliente Gemini en Jython que maneja el historial de conversación.
def send_message(self, user_prompt, initial_prompt=None):
# Añadir mensajes al historial
if not self.history and initial_prompt is not None:
self.history.append({"role": "user", "parts": [{"text": initial_prompt}]})
self.history.append({"role": "user", "parts": [{"text": user_prompt}]})
# Construir y enviar payload
payload = self._build_payload()
response = self._send_request(payload)
# Procesar respuesta
generated_text = self._parse_response(response)
self.history.append({"role": "model", "parts": [{"text": generated_text}]})
return generated_text
Procesamiento de respuestas Json
Una de las partes más críticas fue el parseo de las respuestas Json del LLM. Muchas veces el LLM mezclaba la respuesta estructurada junto con comentarios, preguntas o peticiones de aclaraciones o información, y habia que separar la respuesta extructurada, el Json, del resto de la conversación.
def extraer_json_de_markdown(texto_completo):
marca_inicio = u'```json'
marca_fin = u'```'
pos_inicio = texto_completo.find(marca_inicio)
if pos_inicio != -1:
pos_contenido_inicio = pos_inicio + len(marca_inicio)
pos_fin = texto_completo.find(marca_fin, pos_contenido_inicio)
if pos_fin != -1:
json_encontrado = texto_completo[pos_contenido_inicio:pos_fin].strip()
return json_encontrado, texto_completo[:pos_inicio] + texto_completo[pos_fin + len(marca_fin):]
return None, texto_completo
Reflexiones… y una pregunta incómoda
Este primer prototipo me demostró varias cosas importantes:
- No necesitas frameworks complejos para empezar a integrar IA en aplicaciones legacy.
- El prompting estructurado es la clave: Puedes “programar” el comportamiento de un LLM con instrucciones precisas.
- Java/Jython y las librerías estándar son suficientes para comunicarse con APIs modernas.
Tenía una prueba de concepto que funcionaba. Pero mientras veía las respuestas de la IA aparecer en la pantalla, una pregunta empezó a rondarme la cabeza, una que podia convertir este experimento en un simple juguete personal.
Cada una de esas respuestas “mágicas” requería una llamada a una API de pago. ¿Cómo iba a compartir esto con alguien sin que ni ellos ni yo nos arruinásemos en el intento? ¿Pedirle a los usuarios que consiguieran su propia API Key solo para probar mi herramienta? No parecia realista.
De repente, el mayor desafío ya no era técnico, sino de distribución. Pero antes de poder resolver ese problema, necesitaba que la herramienta fuera tan útil, tan indispensable, que mereciera la pena luchar por ella. Tenía que dejar de ser un chat para convertirse en un verdadero asistente que entendiera el contexto de lo que el usuario estaba haciendo en gvSIG desktop.
De eso, y de cómo el contexto lo cambió todo, hablaré en el siguiente artículo.
Un saludo.